Internet Explorer As A Service
I ran across an interesting artifact while exploring a memory image from a case with Volatility and Evolve. It looked bad at first glance, but turned out to be normal behavior as designed by Microsoft. I want to share a bit of the story with you, and then give you the facts of the behavior.
I had posted a tweet about a somewhat related topic, and @davehull pointed out that Internet Explorer in Windows 8 runs differently when started as a Metro app. The IE process sits as a child of svchost.exe in the process tree. I did some testing and confirmed the behavior. I tested in Windows 10 and found a little change. Then, @hexacorn (Adam) threw a twist in with a line of vbscript. Keep reading, and I will explain all of this.
Metro App Verses Regular App
Let me first clear the air and make sure that everyone reading is following what I am talking about with the Windows 8 Metro app. The start menu in Windows 8 is a full screen experience. There are tiles on this menu that will launch an application. One of the tiles you will see below is for Internet Explorer.
When you click on this tile, it launch Internet Explorer in the Metro version, and it looks a little something like this.
Alternatively, when you are in the desktop experience by clicking on the desktop tile, you will find a link to Internet Explorer pinned to the start bar.
Process Tree Examples
For years, processes have traditionally started in Windows in the same way. If the user initiates the process, it is typically put as a child of the process that was used to kick it off. When started from the start menu, link file, or run box, it will typically sit as a child of explorer.exe. If the process is designed to be run non-interactively in the background, it will typically sit as a child under services.exe.
Let me give a basic example to illustrate. I am using a Windows 8 machine for this, but you can follow along and see this functionality with any version of Windows.
1. Open the calculator.
2. Open the command prompt. Type calc.exe and hit [enter]
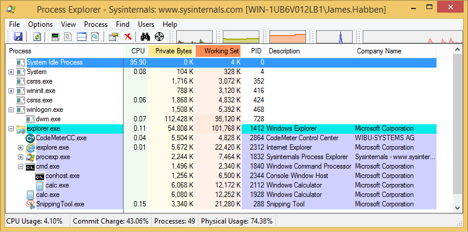
You will end up with a process tree looking something like this in Process Explorer. One calc.exe is a child of explorer.exe, along side with the cmd.exe that we opened. The other calc.exe is a child of cmd.exe.
Hosting the Party
The processes that run in the background sit under services.exe which is a child of wininit.exe. A very common process to find in this area is svchost.exe. In the image below, I have 13 instances of svchost.exe running. Each of them serves a different purpose, but I won’t go into that here. The point of showing you this is to show you where and how svchost.exe is used.
I also want to show you the permissions assigned to the svchost.exe process. You can right click on any one of those instances and click on properties. You will need to make sure that Process Explorer is running in admin mode first, however. Notice that the User running the process is NT AUTHORITY\SYSTEM. The quick assumption every examiner makes is that any child process of svchost.exe will also inherit the permissions of SYSTEM. This is not always the case, but it is very common. It is safe to assume this at first, and prove it wrong with a little bit of work.
(Mis)Behavior at Hand
After establishing the baseline above, tell me if this looks normal or a bit off to you.
I hope that you had all sorts of bells and whistles going off in your head. Unless you have seen this artifact before and have chased it down, this looks downright scary.
You might have also noticed that opening one window of the Metro Internet Explorer actually created a parent and child iexplore.exe, and good for you! I will just say simply that each tab gets a process, for now, since I am planning on another blog post to explain that part.
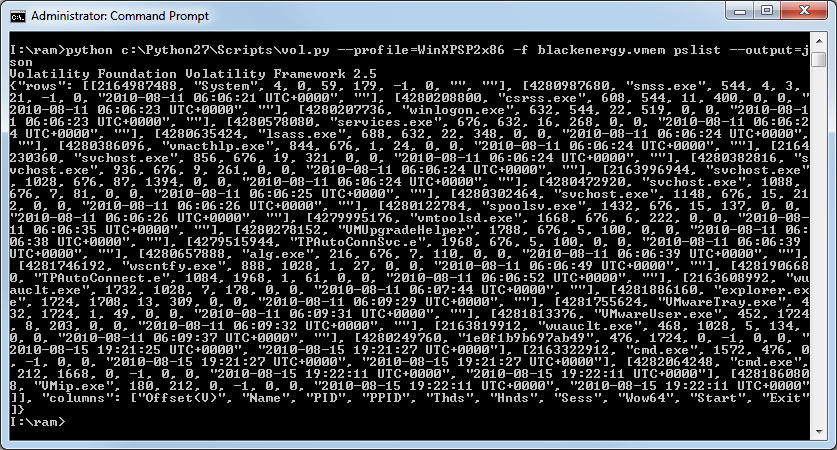
Now I will look at this in Evolve, since this is how it all started for me. Follow along with me by downloading the memory image. Looking at the output for the Volatility pslist module shows me several instances of iexplore.exe, and it sticks out to me that there are a number of different PPID values. Typing IE into the search box narrows down the results to just those of iexplore.exe processes.
To get a better picture, I use the Show SQL button to input a custom SQL query. I want to show the name of the parent process so I don’t have to keep searching on the PID values.
SELECT p1.*,
(select name from pslist p2 where p2.pid=p1.ppid) as Parent
FROM pslist p1
Once the SQL is applied I hide several of the columns, and drag the parent column over beside the PPID column.
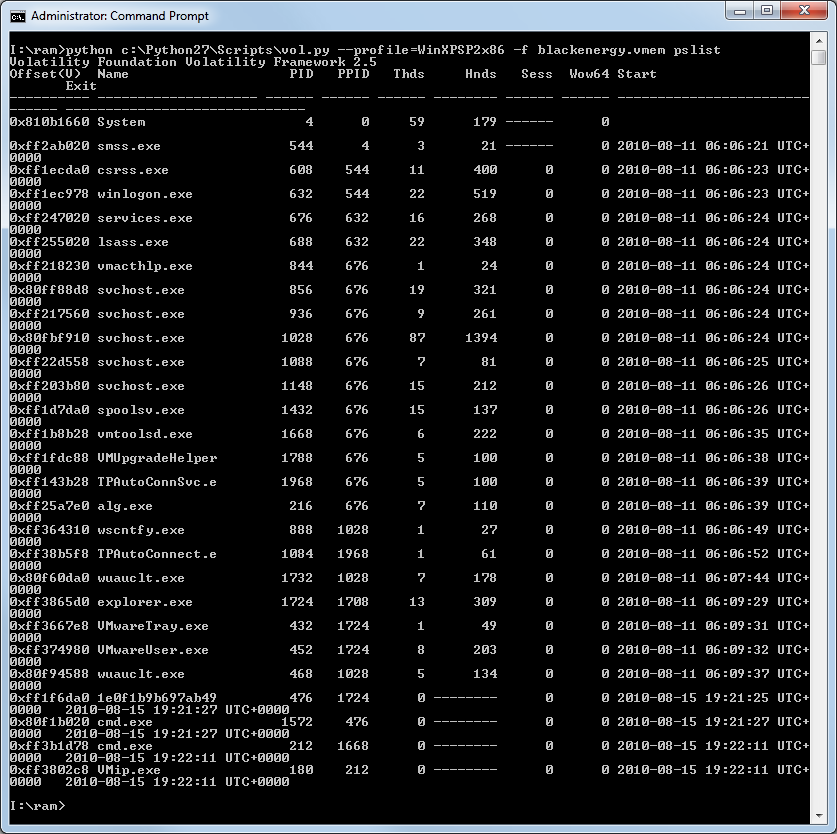
If you use Volatility from your shell, you can run the pstree module and see it pretty well in the output like this.
If I didn’t know any better (which is the point of writing this blog post) I would assume that the iexplore.exe processes under svchost.exe are running with SYSTEM privileges. So I make that assumption and investigate a little further to prove it wrong.
I run the Volatility getsids module and view the output in Evolve. In the search box, I type ‘ie sys’ and I get no results.
This causes me to think I did something wrong, so I back out and just type ‘sys’ and find there is a lot of noise. I continue in the search box with ‘sys loc’ which seems to do the trick. I also hide a couple columns to improve the view. Scrolling through this list shows all the processes I expect to have SYSTEM privileges, but I don’t see any iexplore.exe entries in the list.
I want to confirm all of this, so I clear the search box and type ‘iex’. I get all of the sids associated with all of the iexplore.exe processes, and none of them hold SYSTEM elevated privileges. These processes have the Administrators group since I am logged into that VM with an admin account.
The Change-up in Windows 10
Microsoft decided to change the name of Internet Explorer for the release of Windows 10. They also changed the way the processes are created a little bit. The parent MicrosoftEdge.exe process becomes a child of svchost.exe, but the tabs don’t fall under it. The tabs end up being children of a different process called RuntimeBroker.exe which is itself a child of svchost.
So, you can the changes in Windows 10 aren’t drastic, but they are enough to note for future investigations.
Adam’s Screwball
You probably know Adam best from his massive series of Hexacorn blog posts about various autorun locations that can be used for persistence by malicious software. If not, you should go read them when you finish here.
Adam joined the conversation on twitter and pointed out that you could emulate the behavior of the Metro IE with a single line of vbscript to start it off. Controlling it would require a few more lines, but thats not the point here. Let me show you the line of code.
Set ie=WScript.CreateObject(“InternetExplorer.Application”)
It’s pretty simple to kick this off. Just type or paste that line of code into a text file, and save it as a .vbs file. Open your command prompt, navigate to the folder where you saved it, and use cscript to execute it.
Here comes the test, are you ready? I rebooted my VM so you can cheat by using the previous PID numbers, though I applaud your attempt. Which process was started by the vbscript? First the parent processes, and then the children.
Since I don’t want to intrusively blast jeopardy music through your browser, I will attempt an equivalent measure of stalling for time so you don’t accidentally cheat.
An excerpt for your reading pleasure:
Last week, we met to address your continuing job-performance problems related to the serving of items from the dessert cart you operate in the newspaper’s senior staff dining room. These problems have persisted despite repeated counseling sessions with supervisors as well as staff training programs. Specifically, your refusal to serve dessert to certain members of the senior staff has resulted in several written complaints from administrators at this company.
Mrs. Lopez, your refusal to serve dessert to certain members of the paper’s staff is disruptive to food service operations, and the explanations that you have provided for your behavior are not acceptable. This letter is being issued as a written warning with the expectation that there will be an immediate and sustained improvement in your job performance. Failure to comply will result in further disciplinary action.
On a more personal note, Mrs. Lopez, please stop refusing to give senior staff members dessert, even if you feel, as you explained to me last week, that they don’t “deserve it.” Which members of the paper’s staff do or do not deserve dessert is not your decision to make! And I would hate to see you asked to leave the food craft services department over something so silly! I would really miss you — and your chocolate chip cookies!
The only difference that any of us, from the twitter dialog, could come up with was that the tab opened by vbscript ended up being a 32-bit process. Adam and I both tried a number of ways to get it running fully as a 64-bit process, but we both failed. If you come up with a technique to make that happen, please let me know!
Good, Bad, and Badly Designed
With that, I have shown you what appeared to be bad, but ended up being good – as badly designed. I have also shown you some bad which does a pretty darn good job at looking like the good.
Hope you found this interesting and useful. Happy Hunting!
Get the memory image I was looking through.
James Habben
@JamesHabben Continue reading Analyzing IEaaS in Windows 8→