By Gerardo Fernández, Joseliyo Sánchez and Vicente Díaz
Malware analysis is (probably) the most expert-demanding and time-consuming activity for any security professional. Unfortunately automation for static analysis has always been challenging for the security industry. The sheer volume and complexity of malicious code necessitate innovative approaches for efficient and effective analysis. At VirusTotal, we’ve been exploring the potential of Large Language Models (LLMs) to revolutionize malware analysis. We started this path last April 2023 by automatically
analyzing malicious scripts, and since then, we evolved our model to analyze
Windows executable files. In this post, we want to share part of our current research and findings, as well as discuss future directions in this challenging approach.
Our approach
As a parallel development to the architecture described in our previous
post, we wanted to better understand what are the strengths and limitations of LLMs when analyzing PE files. Our initial approach using memory dumps from sandbox detonation and backscatter for additional deobfuscation capabilities (which will likely be the biggest challenge for the analysis) sounds like a great approach, however rebuilding binaries from memory dumps has its own problems and all this process takes additional time and computational resources – maybe it won’t be necessary for every sample! Thus, the importance of understanding what LLMs can and can’t do when faced with a decompiled (or disassembled) binary.
We also want to consider additional tools we might use to provide the LLMs with additional context, including our sandbox analysis. For decompilation we will be using Hex-Rays IDA Pro most of the time, however our approach will be using a “decision tree” to optimize what tools, prompts and additional context to use in every case.
Our LLM of choice will be Gemini 1.5. The extended token capabilities is what in essence allows us to analyze decompiled and disassembled code, as well as providing additional context on top of any prompt we use.
Malware analysis
To get some understanding of the malware analysis capabilities of Gemini, we used a set of samples for different representative malware families. We used backscatter to determine the malware family every sample belonged to, and we chose only malicious samples for this part of the experiment. When the LLM was asked if the samples were malicious, these are the results per family:
The global result is that LLMs agreed on maliciousness 84% of the time, couldn’t determine (unknown) 12%, and provided a False Negative 4%.
It is interesting to note how results greatly vary amongst families, however this was suspected as different malware uses different obfuscation/packing/encryption methods. For instance, Nanocore uses AutoIT to build their binaries, something that the LLM is not ready to deal with natively. This is a good example of how we build our decision tree – if AutoIT is detected, we definitely will need to unpack first.
One of the biggest advantages of LLMs is that they can provide a full explanation of the reasoning behind a verdict. For “unknown” maliciousness, it is interesting to note that the analysis included several red flags detected by the LLM, however they were not enough to go for a “malicious” verdict. We believe this can also be fine tuned with better prompting, adjusting temperature and further training.
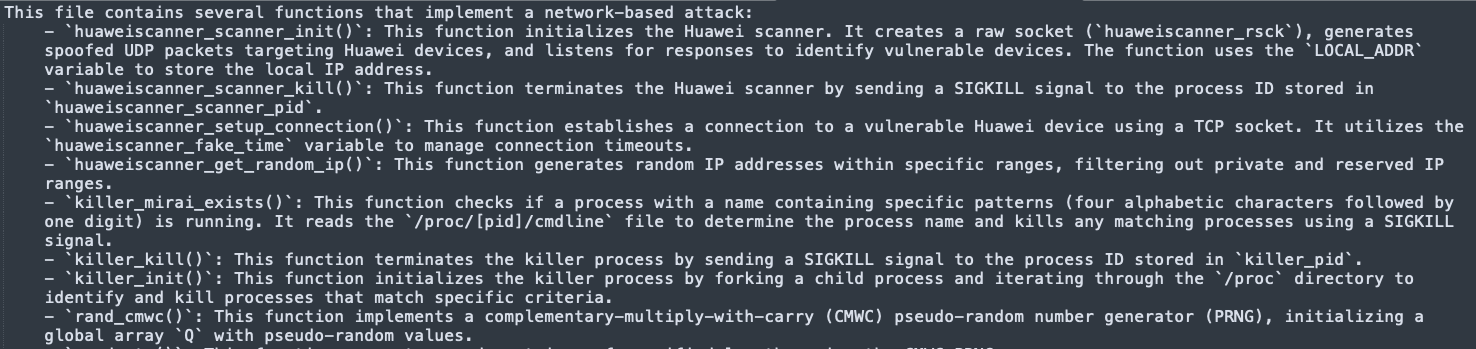
We also found illustrative examples during our analysis. For instance, for some njRAT samples, the LLM returned some IOCs, as seen in the image below:
Information returned by the LLM
Interestingly, they are provided “right to left”. We also believe that we can improve mechanisms to double check IOCs, for instance through the use of API Function Calls to VirusTotal.
In best case scenario, like when analyzing some Mirai samples, the output from the LLM will provide all details, including all the commands accepted by the malware:
Consistent Output
Given LLMs are non deterministic, one of the difficulties in analyzing LLM output is providing consistent results. We found this specially relevant in some families, being Qakbot one example: when the LLM cannot analyze parts of the code given to obfuscation/encryption, it naturally focuses on the rest, meaning that the output describing the capabilities varies drastically between samples. Although this is understandable and solvable through the decision tree to provide the LLM with a more consistent input, we also would like to explore how we can get a more consistent output.
We explored what we initially thought would be a good idea: asking Gemini to provide its output using
CAPA ontology. This would provide a reasonable answer from the LLM by standardizing its output using a series of well defined capabilities, as well as allow us to compare results with our sandbox output, which would allow us to double-check the integrity of LLM’s results.
This idea, unfortunately, didn’t work as expected. There are many capabilities that are easy to detect dynamically in execution but difficult to identify statically and vice versa. Additionally, CAPA’s output is based on a series of rules (similar to YARA), which don’t necessarily work consistently for every single capability.
Prompt evolution
This was one of the key points during our research. We’ve experimented with various prompt engineering techniques to improve the accuracy and comprehensiveness of LLM-generated analysis reports, increasingly adding additional context to the LLM. As we progressed in the investigation, we started providing dynamic execution details along with the decompiled code, providing way better results: at the end of the day, this allows us to combine both dynamic and static analysis.
Encouraged with the good results, we added more context information from what we knew about the sample in VirusTotal: details on related IOCs, configuration extracted from the samples, etc. For example, if the analyzed sample drops another file during execution, we can provide the full VirusTotal report of said dropped. This can help disambiguate situations where other security tools hesitate if the sample is a legitimate installer or drops malware, which is of great relevance. However, we also discovered that we need to be very cautious about the information we provide in the prompt, as this might lead to the LLM biasing its analysis based on it. For instance, if *seems* it might give more weight to some details provided in the prompt that could affect its analysis of the code.
We found that a good solution to both provide all the needed details to the LLM without biasing its answer was using Gemini’s
function calling, which allows Gemini to dynamically request context data as needed using API calls to VirusTotal.
Conclusion
Our ongoing research into LLM-powered malware analysis has yielded promising results, demonstrating the potential of this technology to transform the way we detect and respond to threats. While challenges remain, we’re confident that continued advancements in LLMs, our understanding of their capabilities and our improvement in our analysis decision tree will lead to even more effective and efficient malware analysis solutions.
Importantly, we believe that LLM analysis is not intended to replace human reverse engineers anyhow, but rather to augment their capabilities. By automating routine tasks and providing valuable insights, LLMs can empower analysts to focus on more complex and critical aspects of malware analysis, ultimately enhancing our collective ability to combat cyber threats. In addition, LLM capabilities can be of great help for most security practitioners without the in-depth knowledge necessary for reverse engineering or without the need of getting a profound understanding of every single aspect of the malware analyzed.
We’re committed to sharing our findings with the security community and collaborating with researchers and practitioners to further advance the field of LLM-driven malware analysis. As we continue to explore the possibilities of this exciting technology, we’re optimistic about the future of AI-powered malware analysis.
Continue reading Leveraging LLMs for Malware Analysis: Insights and Future Directions→