Yes, we’ve definitely spent our share of toolsmith time on memory analysis tools such as Volatility and Rekall, but for good reason. I contend that memory analysis is fundamentally one of the most important skills you’ll develop and utilize throughout your DFIR career.
By now you should have read The Art of Memory Forensics, if you haven’t, it’s money well spent, consider it an investment.
If there is one complaint, albeit a minor one, that analysts might raise specific to memory forensics tools, it’s that they’re very command-line oriented. While I appreciate this for speed and scripting, there are those among us who prefer a GUI. Who are we to judge? 🙂
Kevin Breen’s (@kevthehermit) VolUtility is a full function web UI for Volatility which fills the gap that’s been on user wishlists for some time now.
When I reached out to Kevin regarding the current state of the project, he offered up a few good tidbits for user awareness.
1. Pull often. The project is still in its early stages and its early life is going to see a lot of tweaks, fixes, and enhancements as he finishes each of them.
2. If there is something that doesn’t work, could be better, or removed, open an issue. Kevin works best when people tell him what they want to see.
3. He’s working with SANS to see VolUtility included in the SIFT distribution, and release a Debian package to make it easier to install. Vagrant and Docker instances are coming soon as well.
The next two major VolUtility additions are:
1. Pre-Select plugins to run on image import.
2. Image Threat Score.
Notifications recently moved from notification bars to the toolbar, and there is now a right click context menu on the plugin output, which adds new features.
Installation
VolUtility installation is well documented on its GitHub site, but for the TLDR readers amongst you, here’s the abbreviated version, step by step. This installation guidance assumes Ubuntu 14.04 LTS where Volatility has not yet been installed, nor have tools such as Git or Pip.
Follow this command set verbatim and you should be up and running in no time:
- sudo apt-get install git python-dev python-pip
- git clone https://github.com/volatilityfoundation/volatility
- cd volatility/
- sudo python setup.py install
- sudo apt-key adv –keyserver hkp://keyserver.ubuntu.com:80 –recv 7F0CEB10
- echo “deb http://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/3.0 multiverse” | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
- sudo apt-get update
- sudo apt-get install -y mongodb-org
- sudo pip install pymongo pycrypto django virustotal-api distorm3
- git clone https://github.com/kevthehermit/VolUtility
- cd VolUtility/
- ./manage.py runserver 0.0.0.0:8000
Point your browser to http://localhost:8000 and there you have it.
VolUtility and an Old Friend
I pulled out an old memory image (hiomalvm02.raw) from September 2011’s toolsmith specific to Volatility where we first really explored Volatility, it was version 2.0 back then. 🙂 This memory image will give us the ability to do a quick comparison of our results from 2011 against a fresh run with VolUtility and Volatility 2.5.
VolUtility will ask you for the path to Volatility plugins and the path to the memory image you’d like to analyze. I introduced my plugins path as /home/malman/Downloads/volatility/volatility/plugins.
The image I’d stashed in Downloads as well, the full path being /home/malman/Downloads/HIOMALVM02.raw.
Upon clicking Submit, cats began loading stuffs. If you enjoy this as much as I do, the Help menu allows you to watch the loading page as often as you’d like.
If you notice any issues such as the image load hanging, check your console, it will have captured any errors encountered.
On my first run, I had not yet installed distorm3, the console view allowed me to troubleshoot the issue quickly.
Now down to business. In our 2011 post using this image, I ran imageinfo, connscan, pslist, pstree, and malfind. I also ran cmdline for good measure via VolUtility. Running plugins in VolUtility is as easy as clicking the associated green arrow for each plugin. The results will accumulate on the toolbar and the top of the plugin selection pane, while the raw output for each plugin will appears beneath the plugin selection pane when you select View Output under Actions.
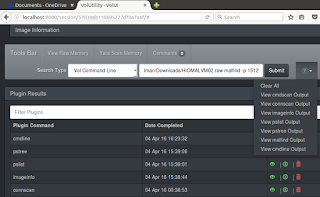
Results were indeed consistent with those from 2011 but enhanced by a few features. Imageinfo yielded WinXPSP3x86 as expected, connscan returned 188.40.138.148:80 as our evil IP and the associated suspect process ID of 1512. Pslist and pstree then confirmed parent processes and the evil emanated from an ill-conceived click via explorer.exe. If you’d like to export your results, it’s as easy as selecting Export Output from the Action menu. I did so for pstree, as it is that plugin from whom all blessings flow, the results were written to pstree.csv.
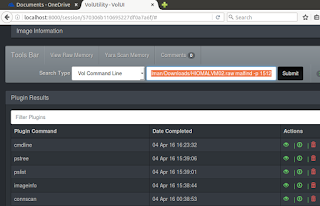
We’re reminded that explorer.exe (PID 1512) is the parent for cleansweep.exe (PID 3328) and that cleansweep.exe owns no threads current threads but is likely the original source of pwn. We’re thus reminded to explore (hah!) PID 1512 for information. VolUtility allows you to run commands directly from the Tools Bar, I did so with vol.py -f /home/malman/Downloads/HIOMALVM02.raw malfind -p 1512.
Rather than regurgitate malfind results as noted from 2011 (you can review those for yourself), I instead used the VolUtility Tools Bar feature Yara Scan Memory. Be sure to follow Kevin’s Yara installation guidance if you want to use this feature. Also remember to git pull! Kevin updated the Yara capabilities between the time I started this post and when I ran yarascan. Like he said, pull often. There is a yararules folder now in the VolUtility file hierarchy, I added spyeye.yar, as created from Jean-Philippe Teissier’s rule set. Remember, from the September 2011 post, we know that hiomalvm02.raw taken from a system infected with SpyEye. I then selected Yara Scan Memory from the Tools Bar, and pointed to the just added spyeye.yar file.
The results were immediate, and many, as expected.
You can also use String Search / yara rule from the Tools Bar Search Type field to accomplish similar goals, and you can get very granular with you string searches to narrow down results.
Remember that your sessions will persist thanks to VolUtility’s use of MongoDB, so if you pull, then restart VolUtility, you’ll be quickly right back where you left off.
In Closing
VolUtility is a great effort, getting better all the time, and I find its convenience irresistible. Kevin’s doing fine work here, pull down the project, use it, and offer feedback or contributions. It’s a no-brainer for VolUtility to belong in SIFT by default, but as you’ve seen, building it for yourself is straightforward and quick. Add it to your DFIR utility belt today.
As always, ping me via email or Twitter if you have questions: russ at holisticinfosec dot org or @holisticinfosec.
ACK
Thanks to Kevin (@kevthehermit) Breen for VolUtility and his feedback for this post. Continue reading toolsmith #115: Volatility Acuity with VolUtility→















