Hardware Store Marauder’s Map is Clarkian Magic
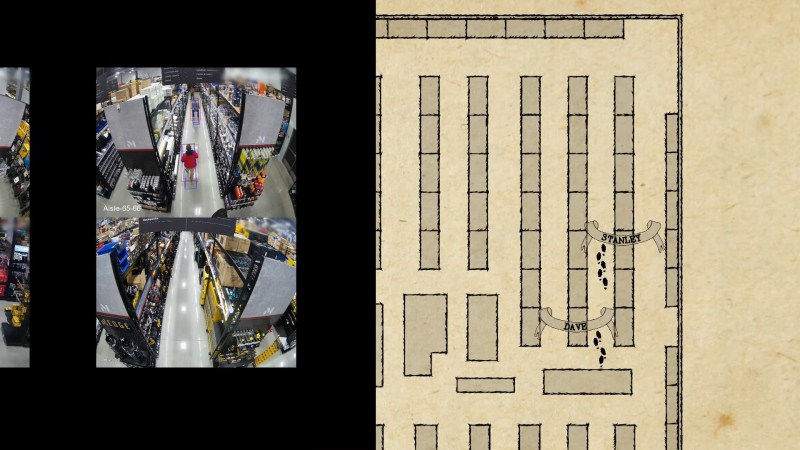
The “Marauder’s Map” is a magical artifact from the Harry Potter franchise. That sort of magic isn’t real, but as Arthur C. Clarke famously pointed out, it doesn’t need to …read more Continue reading Hardware Store Marauder’s Map is Clarkian Magic
