Squirrelling Away Plists
 |
| Just grabbin some acorns … |
Plists are Apple’s way of retaining configuration information. They’re scattered throughout OS X and iOS like acorns and come in 2 main types – XML and binary. Due to their scattered nature and the potential for containing juicy artefacts, monkey thought a script to read plists and extract their data into an SQLite database might prove useful. The idea being analysts run the script (plist2db.py) against a directory of plists and then browse the resultant table for any interesting squirrels. Analysts could also execute the same queries against different sets of data to find common items of interest (eg email addresses, filenames, usernames).
Similar in concept to SquirrelGripper which extracted exiftool data to a DB, the tool will only be as good as the data fields extracted and the analyst’s queries. At the very least, it allows analysts to view the contents of multiple plists at the same time. Plus we get to try out Python 3.4’s newly revised native “plistlib” which now parses BOTH binary and XML plists. Exciting times!
Not having easy access to an OS X or iOS system, monkey is going to have to improvise a bit for this post and also rely upon the kindness of plist donaters. Special Thanks to Sarah Edwards (@iamevltwin) and Mari DeGrazia (@maridegrazia) for sharing some sample plists used for testing.
XML based plists are text files which can be read using a text editor. Binary plists follow a different file format and typically require a dedicated reader (eg plist Editor Pro) or conversion to XML to make it human readable.
Both types of plist support the following data types:
CFString = Used to store text strings. In XML, these fields are denoted by the <string> tag.
CFNumber = Used to store numbers. In XML, the <real> tag is used for floats (eg 1.0) and the <integer> tag is used for whole numbers (eg 1).
CFDate = Used to store dates. In XML, the <date> tag is used to mark ISO formatted dates (eg 2013-11-17T20:10:06Z).
CFBoolean = Used to store true/false values. In XML, these correspond to <true/> or <false/> tags.
CFData = Used to store binary data. In XML, the <data> tag marks base64 encoded binary data.
CFArray = Used to group a list of values. In XML, the <array> tag is used to mark the grouping.
CFDictionary = Used to store sets of data values keyed by name. Typically data is grouped into dictionaries with <key> and <value> elements. The <key> fields use name strings. The <value> elements are typically one of the following – <string>, <real>, <float>, <date>, <true/>, <false/>, <data>. The order of key declaration is not significant. In XML, the <dict> tag is used to mark the dictionary boundaries.
To show how it all fits together, let’s take a look an XML plist example featuring everyone’s favourite TV squirrel …
<?xml version=”1.0″ encoding=”UTF-8″?>
<!DOCTYPE plist PUBLIC “-//Apple//DTD PLIST 1.0//EN” “http://www.apple.com/DTDs/PropertyList-1.0.dtd”>
<plist version=”1.0″>
<dict>
<key>Name</key>
<string>Rocket J. Squirrel</string>
<key>Aliases</key>
<array>
<string>Rocky the Flying Squirrel</string>
<string>Rocky</string>
</array>
<key>City of Birth</key>
<string>Frostbite Falls</string>
<key>DNA</key>
<data>
cm9ja3ktZG5hCg==
</data>
<key>Year Of Birth</key>
<integer>1959</integer>
<key>Weight</key>
<real>2.5</real>
<key>Flight Capable</key>
<true/>
</dict>
</plist>
Note: The DNA <data> field “cm9ja3ktZG5hCg==” is the base64 encoding of “rocky-dna”.
We can cut and paste the above XML into plist Editor Pro and save it as a binary plist.
We can also open a new text file and paste the above XML into it to create an XML plist.
Further Resources
The Mac Developer Library documentation describes Plists here and the Apple manual page describes XML plists here.
Michael Harrington has a great working example / explanation of the binary plist file format here and here.
Setting Up
Using the binary capable “plistlib” requires Python v3.4+. So if you don’t have it installed, you’re gonna be disappointed. Note: Ubuntu 14.04 has Python 3.4 already installed so if you’re already running that, you don’t have to worry about all this setup stuff.
To install Python 3.4 on Ubuntu 12.04 LTS (eg like SANS SIFT 3), there’s a couple of methods.
I used this guide from James Nicholson to install the 3.4.0beta source onto my development VM.
FYI 3.4.1 is currently the latest stable release and should be able to be installed in a similar manner.
There’s also this method that uses an Ubuntu Personal Package Archive from Felix Krull.
But Felix makes no guarantees, so I thought it’d be better to install from source.
Alternatively, you can install Python 3.4.1 on Windows (or for OS X) from here.
Not having a Mac or iPhone, monkey created his own binary and XML plist files. First, we define/save the new binary plist file using plist Editor Pro (v2.1 for Windows), then we copy/paste the XML into new text file on our Ubuntu development VM and save it. This way we can have both binary and XML versions of our plist information. Note: Binary plists created by plist Editor Pro in Windows were read OK by the script in Ubuntu. However, Windows created XML plists proved troublesome (possibly due to Windows carriage returns/linefeeds?) – hence the cut and paste from the XML in plist Editor Pro to the Ubuntu text editor for saving.
For squirrels and giggles, we’ll continue to base our test data on characters from the Rocky and Bullwinkle Show. For those that aren’t familiar with the squirrel and moose, commiserations and see here.
The Script
For each file in the specified input directory (or just for an individual file), the script calls the “plistlib.load()” function.
This does the heavy lifting and returns the “unpacked root object” (usually a dictionary).
The script then calls a recursive “print_object” function (modified/re-used from here) to go into each/any sub-object of the root object and store the filename, plist path and plist value in the “rowdata” list variable.
Once all plist objects have been processed, the script creates a new database using the specified output filename and SQL “replaces” the extracted “rowdata” into a “plists” table. We use SQL “replace” instead of SQL “insert” so we don’t get “insert” errors when running the script multiple times using the same source data and target database file. Although to be prudent, it’s just as easy to define a different output database name each time … meh.
The “plists” table schema looks like:
CREATE TABLE plists(filename TEXT NOT NULL, name TEXT NOT NULL, value TEXT NOT NULL, PRIMARY KEY (filename, name, value) )
Note: The “plists” table uses the combination of filename + name + value as a Primary Key. This should make it impossible to have duplicate entries.
See comments in code for further details.
Testing
To run the script we just point it at a directory or individual plist and give it a filename for the output SQLite database.
Here we are using the python3.4 beta exe from my Ubuntu development VM’s locally installed directory …
cheeky@ubuntu:~/python3.4b/bin$ ./python3.4 /home/cheeky/plist2db.py
Running plist2db.py v2014-07-24Usage: plist2db.py -f plist -d database
Options:
-h, –help show this help message and exit
-f FILENAME XML/Binary Plist file or directory containing Plists
-d DBASE SQLite database to extract Plist data to
cheeky@ubuntu:~/python3.4b/bin$
Here’s how the test data was stored …
cheeky@ubuntu:~/python3.4b/bin$ tree /home/cheeky/test-plists/
/home/cheeky/test-plists/
+– bin-plists
¦ +– boris.plist
¦ +– bullwinkle.plist
¦ +– natasha.plist
¦ +– rocky.plist
+– Red-Herring.txt
+– xml-plists
+– boris-xml.plist
+– bullwinkle-xml.plist
+– natasha-xml.plist
+– rocky-xml.plist2 directories, 9 files
cheeky@ubuntu:~/python3.4b/bin$
Note: “Red-Herring.txt” is text file included to show how non-plist files are handled by the script.
Now we can try our extraction script with our test data …
cheeky@ubuntu:~/python3.4b/bin$ ./python3.4 /home/cheeky/plist2db.py -f /home/cheeky/test-plists/ -d /home/cheeky/bullwinkles.sqlite
Running plist2db.py v2014-07-24*** WARNING /home/cheeky/test-plists/Red-Herring.txt is not a valid Plist!
cheeky@ubuntu:~/python3.4b/bin$
Here is a screenshot of the resultant “bullwinkles.sqlite” database …
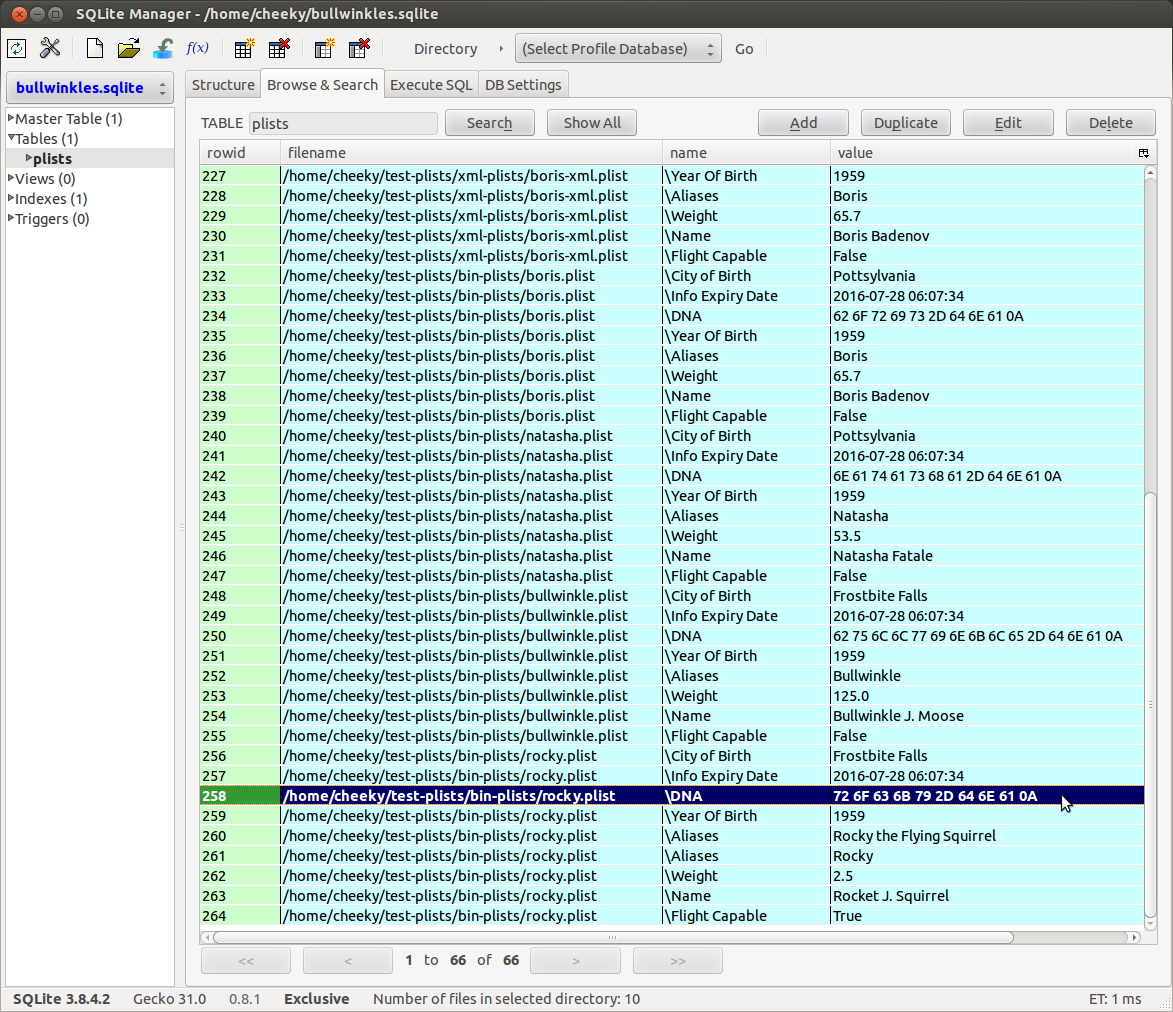 |
| Test Data Output Database |
Note: The XML plist DNA <data> fields shown have been extracted and base64 *decoded* automatically by the “libplist” library. Our test data binary plists store the raw ASCII values we entered and the XML plists store the base64 encoded values. Being text based, I can understand why XML encodes binary data as base64 (so its printable). But binary plists don’t have the printable requirement so there’s no base64 encoding/decoding step and the raw binary values are written directly to the binary plist file.
By having the raw hexadecimal values from the <data> fields in the DB, we can cut and paste these <data> fields into a hex editor to see if there’s any printable characters …
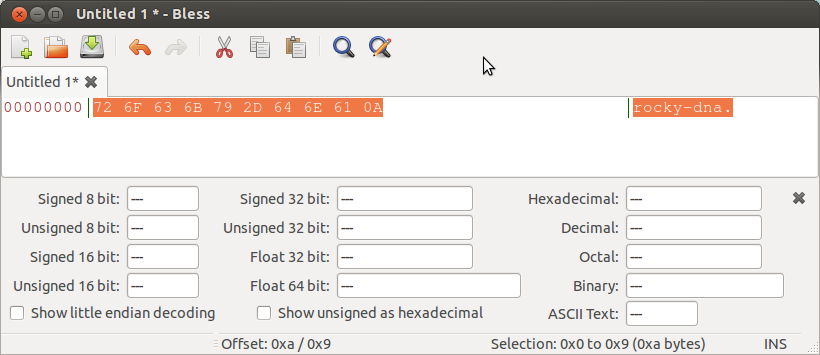 |
| Binary rocky.plist’s DNA data value |
From the previous 2 pictures, we can see that the “DNA” value from our binary “rocky.plist” is actually UTF-8/ASCII for “rocky-dna”.
One nifty feature of plist Editor Pro is that from the “List view” tab, you can double click on a binary value represented by a “…” and it opens the data in a hex editor window. This binary inspection would be handy when looking at proprietary encoded data fields (eg MS Office FileAlias values). Or we could just run our script as above and cut and paste any <data> fields to a hex editor …
From our results above, we can also see that the “Red-Herring.txt” file was correctly ignored by the script and that a total of 66 fields were extracted from our binary and XML plists (as expected).
Now we have a database, we can start SQL querying it for values …
As the “name” and “value” columns are currently defined as text types, limited sorting functionality is available.
Here are a few simple queries for our test data scenario. Because our test plists are not actual OS X / iOS plists, you’ll have to use your imagination/your own test data to come up with other queries that you might find useful/practical. More info on forming SQLite queries is available here.
Find distinct “Aliases”
SELECT DISTINCT value FROM plists
WHERE name LIKE ‘%Alias%’;
Find all the values from the “rocky-xml.plist”
SELECT * FROM plists
WHERE filename LIKE ‘%rocky-xml.plist’;
Find/sort records based on “Weight” value
SELECT * FROM plists
WHERE name LIKE ‘%Weight’ ORDER BY value;
Note: Sort is performed textually as the value column is TEXT.
So the results will be ordered like 125.0, 125.0, 2.5, 2.5, 53.5, 53.5, 65.7, 65.7.
Find/sort records by “Info Expiry Date” value
SELECT * FROM plists
WHERE name LIKE ‘%Info Expiry Date’ ORDER BY value;
Note: This works as expected as the date text is an ISO formatted text string.
The script has been developed/tested on Ubuntu 12.04 LTS (64bit) with Python 3.4.0beta.
It was also tested (not shown) with OS X MS Office binary plists, a Time Machine binary backup plist and a cups.printer XML plist.
Additionally, the script has been run with the bullwinkle test data on Win7 Pro (64 bit) with Python 3.4.1 and on a Win 8.1 Enterprise Evaluation (64 bit) VM with Python 3.4.1
Final Words
The idea was to write a script that grabs as much plist data as it can and leave it to the analyst to formulate their own queries for finding the data they consider important.
The script also allowed monkey to sharpen his knowledge on how plists are structured and granted some valuable Python wrestling time (no, not like that!).
By re-using a bunch of existing Python libraries/code, the script didn’t take much time (or lines of code) to put together.
The native Python “plistlib” also allows us to execute on any system installed with Python 3.4 (OS X, Windows, Linux) without having to install any 3rd party libraries/packages.
I have not been able to run/test it on a complete OS X system (or on iOS plist files) but in theory it *should* work (wink, wink). I am kinda curious to see how many plists/directories it can process and how long it takes. The bullwinkle test data took less than a second to execute.
Depending on what artefacts you’re looking for, you can use the script as an application artefact browsing tool or by using the same queries on data from different sources, you could use it to detect known keywords/values (eg IP theft email addresses, app configuration). Or perhaps you have a bunch of application directories from an iOS device that you’re curious about. Rather than having to inspect each plist individually, you can run this script once and snoop away.
The sorting could be made more comprehensive if each data type was extracted to it’s own table (ie floats in one table, ints in another). However, given that sorting by time currently works already, that additional functionality might not be much use?
If anyone uses this script, I’d appreciate hearing any feedback either via the comments section below or via email. It’d be nice to know if this script is actually of some use and not just another theoretical tool LOL.